Установка Hadoop
Відповіді на запитання від компанії "Український хостинг".

Хостiнг
Вибір хостiнгу



Для сайтів та інтернет-магазинів
Адміністрування

0
UH.ua - найбільший хостинг України!
безкоштовно з міських телефонів України
| Київ | 044 392-73-56 |
| Харків | 057 728-49-18 |
| Дніпро | 056 790-86-00 |
| Одеса | 048 734-56-54 |
| Львів | 032 229-58-50 |
| Миколаїв | 051 270-12-63 |
| Полтава | 053 262-53-74 |
| Запоріжжя | 061 228-69-91 |
Apache Hadoop є широко використовується в ІТ-індустрії інструментом з відкритим вихідним кодом, призначеним для обробки великих даних.
Перед виконанням інструкції рекомендується створити не root користувача з доступом до sudo (а перед цим підключитися до сервера SSH).
В інструкції використовується текстовий редактор nano, для якого потрібно виконати команду:
yum install nanoОновлюємо систему до останнього стабільного стану за допомогою команди:
sudo yum install epel-release -yНатискаємо Enter.
та команди:
sudo yum update -yНатискаємо Enter. Оновлення може тривати кілька хвилин.
Встановлюємо OpenJDK 8 JRE за допомогою YUM:
sudo yum install -y java-1.8.0-openjdkНатискаємо Enter. Якщо запитує пароль, введіть його.
Перевіряємо установку OpenJDK 8 JRE:
java -versionНатискаємо Enter.
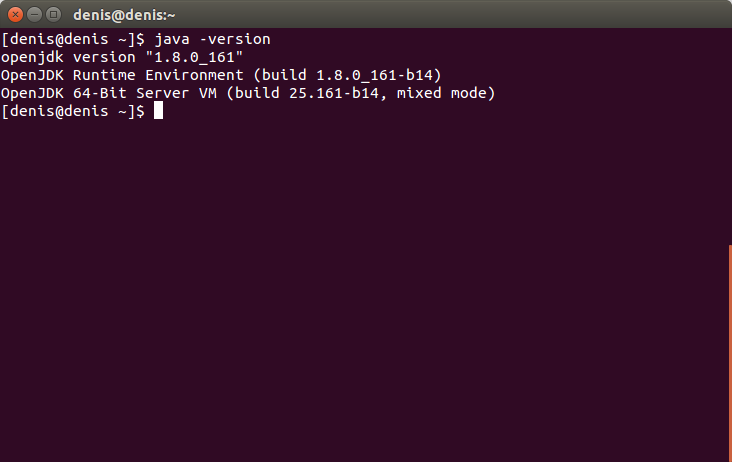
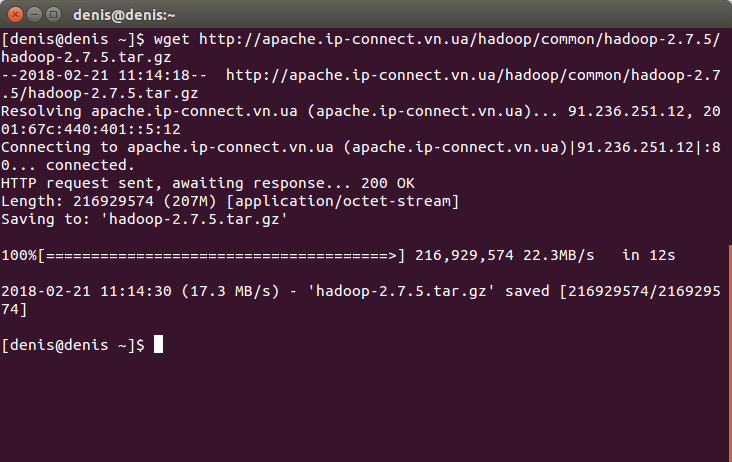
Завантажуємо архів Hadoop:
wget http://apache.ip-connect.vn.ua/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gzНатискаємо Enter.
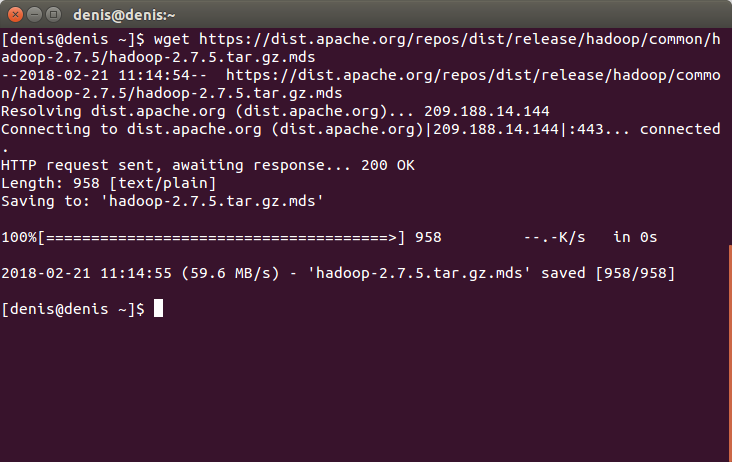
Завантажуємо файл контрольної суми:
wget https://dist.apache.org/repos/dist/release/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz.mdsНатискаємо Enter.
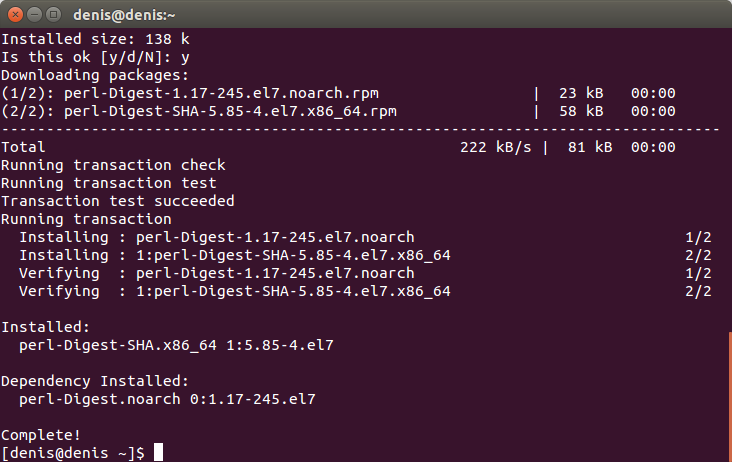
Встановлюємо інструмент контрольної суми:
sudo yum install perl-Digest-SHAНатискаємо Enter. Потім натиснути y та Enter.
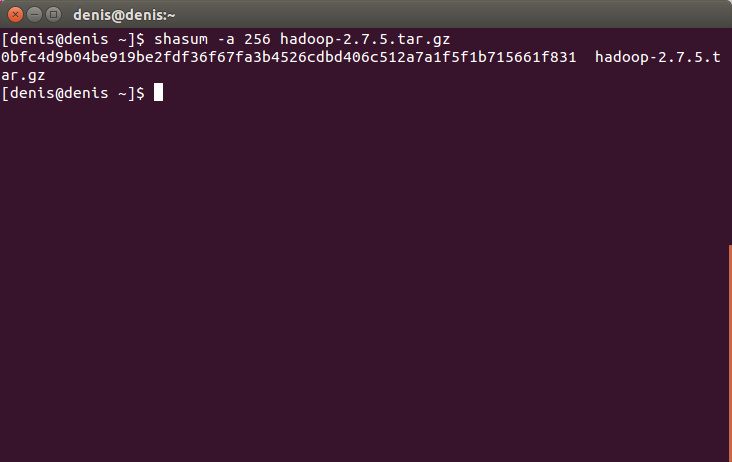
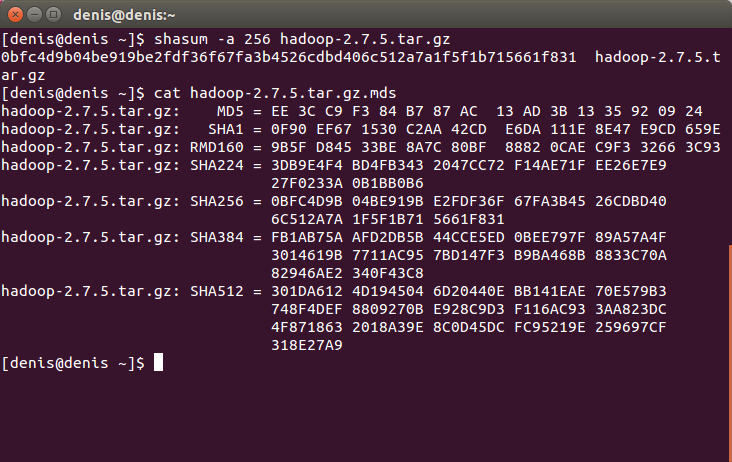
Обчислюємо значення SHA256 архіву Hadoop:
shasum -a 256 hadoop-2.7.5.tar.gzНатискаємо Enter.
Відображаємо вміст файлу hadoop-2.7.5.tar.gz.mds щоб переконатися, що обидва значення SHA256 ідентичні:
cat hadoop-2.7.5.tar.gz.mdsНатискаємо Enter.
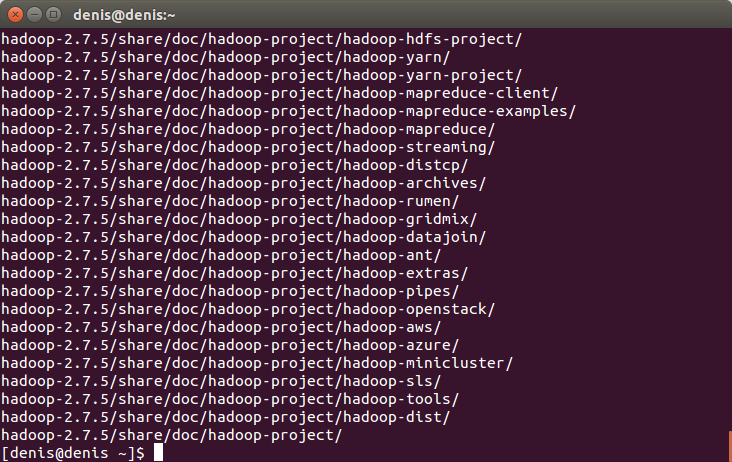
Виймаємо архів у каталог opt:
sudo tar -zxvf hadoop-2.7.5.tar.gz -C /optНатискаємо Enter. Якщо запитує пароль, введіть його
Вказуємо для Hadoop вихідне розташування Java.
Для цього відкриваємо файл конфігурації середовища Hadoop, /opt/hadoop-2.7.5/etc/hadoop/hadoop-env.sh
sudo nano /opt/hadoop-2.7.5/etc/hadoop/hadoop-env.shНатискаємо Enter.
Знаходимо рядок:
export JAVA_HOME=${JAVA_HOME}І міняємо її на стороку:
export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")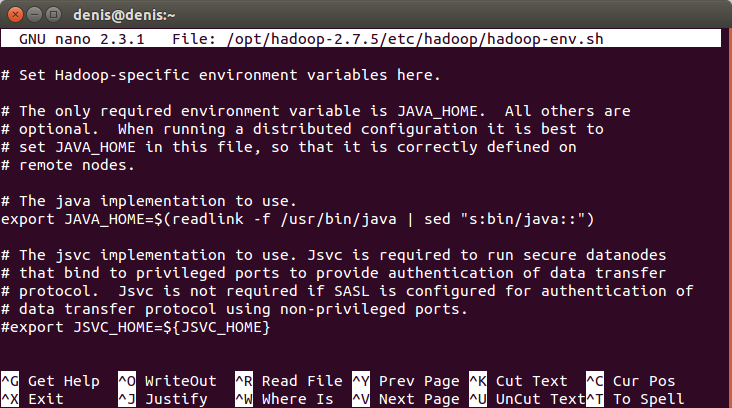
Зберігаємо зміну у файлі, натиснувши клавіші Ctrl+x , потім клавішу y і потім клавішу Enter.
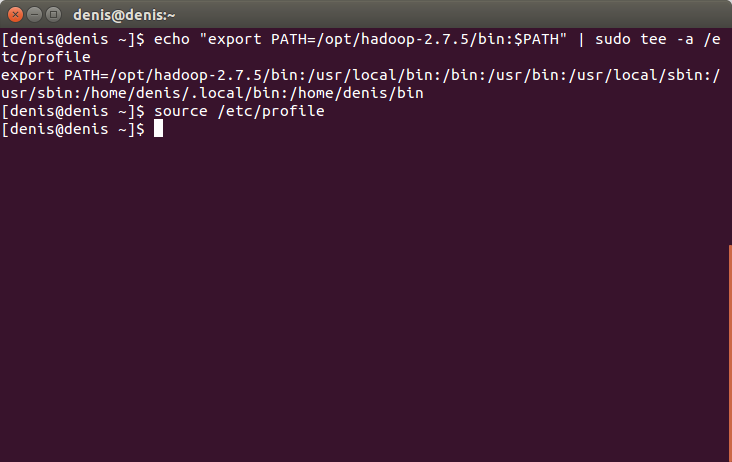
Додаємо шлях Hadoop до PATH змінної оточення.
Виконуємо команду:
echo "export PATH=/opt/hadoop-2.7.5/bin:$PATH" | sudo tee -a /etc/profileНатискаємо Enter.
І команду:
source /etc/profileНатискаємо Enter.
За допомогою вбудованого прикладу Перевіряємо установки Hadoop.
Підготовляємо джерело даних.
Команди:
mkdir ~/sourceНатискаємо Enter.
cp /opt/hadoop-2.7.5/etc/hadoop/*.xml ~/sourceНатискаємо Enter.
Використовуємо Hadoop разом із grep для виведення результату:
hadoop jar /opt/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar grep ~/source ~/output 'principal[.]*'Натискаємо Enter.
Дивимося вміст вихідних файлів:
cat ~/output/*Натискаємо Enter.
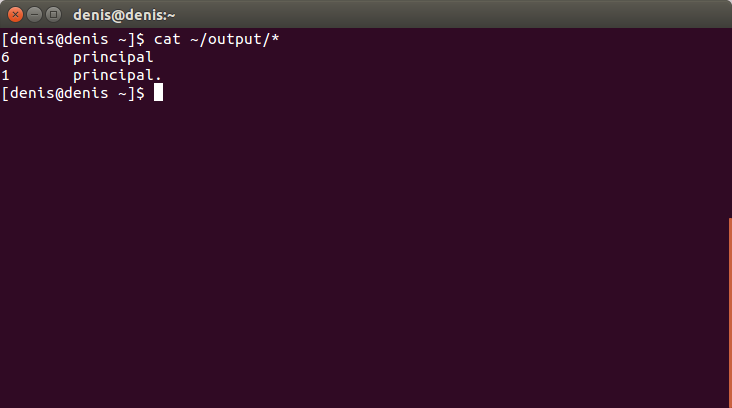
Тепер Hadoop готовий до роботи.
Див. також:
Установка Hadoop

 |
|
 |
 |
 |
 |
 |
|
 |
